
The first thing we need is the ability to control the HS100 smart plug from Tasker on our Android phone. If you haven’t already, be sure to check my preview post where I explain how to create two Tasker Tasks, that will turn our plug On and Off.
For the next step I’ll use the WearTasker: with this app you can choose some of your Tasker tasks and publish them on your watch. They will show as buttons when you open WearTasker on your wrist, and the corresponding task will run when pressed. Quite simple. TBH WearTasker feels like a natural extension of Tasker to Android Wear.
WearTasker - Tasker for Wear (Free+, Google Play) →
You can buy a Pro in-app purchase if you’d like, which unlocks some cool features, but what I use here works with the free version.
So let’s publish both our smart plug tasks. Open Wear Tasker on your phone, and create a new shortcut. Choose your “Power On Plug” task, and name it however you like. You can also select an icon and a color. Then repeat the same operations with the other task:


Back to the app, it should now look like this:

And that’s how it will look on your watch:

Now try to press one of the Task and see how your HS100 smart plug responds!
I love WearTasker. I find it extremely usefull to be able to call Tasker tasks from my watch. Some other tasks I have there are one to power off my home server, one to refresh my Plex library, and one to send a Whatsapp to my wife with my current location and current route ETA.
]]>Please be sure to refer to this post if you are unsure how to obtain the Token and DeviceID that are necessary to control the plug via TP-Link cloud service.
TL;DR: The one-liner below, run in a Linux/Android/Mac shell, will return ON or OFF, indicating what is the state of an HS100 relay:
curl -s --request POST "https://wap.tplinkcloud.com/?token=TOKEN_HERE HTTP/1.1"\ --data '{"method":"passthrough", "params": {"deviceId": "DEVICEID_HERE", "requestData": "{\"system\":{\"get_sysinfo\":null},\"emeter\":{\"get_realtime\":null}}" }}'\ --header "Content-Type: application/json" | grep -q '..relay_state..:1' && echo "ON" || echo "OFF"
I’ve put this line above in a Tasker shell action, and I can perfectly obtain my HS100 state from Tasker now! So cool.
For the one wondering what we can obtain with the get_sysinfo command: run the following line. Here I extract from the Json output the responseData field, which contains the interesting payload, I unescape it with sed, and pretty-format it using json_pp:
curl -s --request POST "https://wap.tplinkcloud.com/?token=TOKEN_HERE HTTP/1.1"\
--data '{"method":"passthrough", "params": {"deviceId": "DEVICEID_HERE", "requestData": "{\"system\":{\"get_sysinfo\":null},\"emeter\":{\"get_realtime\":null}}" }}'\
--header "Content-Type: application/json" | jq ".result.responseData" | sed -e 's#\\\"#"#g; s#^\"##; s#\"$##' | json_pp
The output would be something like this. I’ve masked most of the data for obvious privacy reasons, but you can still get the idea. We see the position, time the device was On, MAC Address, Model, Alias (custom name)…
{
"system" : {
"get_sysinfo" : {
"fwId" : "FWID_HERE",
"relay_state" : 1,
"dev_name" : "Wi-Fi Smart Plug",
"oemId" : "OEMID_HERE",
"on_time" : 451,
"model" : "HS100(EU)",
"icon_hash" : "",
"updating" : 0,
"led_off" : 0,
"err_code" : 0,
"longitude" : LONGITUDE_HERE,
"mac" : "MAC_ADD_HERE",
"hwId" : "HWID_HERE",
"rssi" : -53,
"deviceId" : "DEVICEID_HERE",
"latitude" : LATITUDE_HERE,
"sw_ver" : "1.0.8 Build 151101 Rel.24452",
"alias" : "My Smart Plug",
"type" : "smartplug",
"hw_ver" : "1.0",
"feature" : "TIM",
"active_mode" : "schedule"
}
},
"emeter" : {
"err_msg" : "module not support",
"err_code" : -1
}
}
I guess an HS110 which has some energy consumption colection capability would give more data in the emeter section. Mine is an HS100, and I get “module not support(ed)”. Don’t hesitate to send me some example of an HS110 output energy data, I’ll put them here as well.
We can also extract one particular field’s value using a one-liner like the one below. Here I would extract the value of the relay_state field:
curl -s --request POST "https://wap.tplinkcloud.com/?token=TOKEN_HERE HTTP/1.1"\ --data '{"method":"passthrough", "params": {"deviceId": "DEVICEID_HERE", "requestData": "{\"system\":{\"get_sysinfo\":null},\"emeter\":{\"get_realtime\":null}}" }}'\ --header "Content-Type: application/json" | jq ".result.responseData" | sed -e 's#\\\"#"#g; s#^\"##; s#\"$##' | jq ".system.get_sysinfo.relay_state"]]>
In IFTTT we’ll use the Maker service, which let’s us call a custom HTTP GET/POST request with some Json payload, so that’s exactly what we need here.
 Note: If you haven’t already, follow the steps in my previous post, to figure out what your Token and Device ID are.
Note: If you haven’t already, follow the steps in my previous post, to figure out what your Token and Device ID are.
Then create a new Recipe Applet like you normally would in IFTTT, and choose the “Maker Webhook / Make a Web Request” action service to define a new action.
For the URL, I’ve used:
https://eu-wap.tplinkcloud.com/?token=YOUR_TOKEN_HERE
and the method type is POST.
 Note: For the URL: please read this other post, as you might need to use a different URL depending the region where you are from.
Note: For the URL: please read this other post, as you might need to use a different URL depending the region where you are from.

{kind=link}
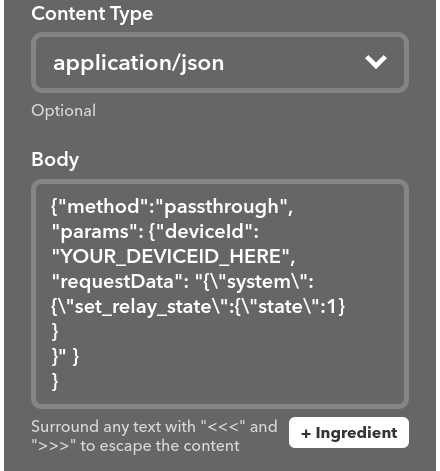
The Content Type is application/json, and the payload to switch the plug On should be:
{"method":"passthrough",
"params": {"deviceId": "YOUR_DEVICEID_HERE",
"requestData": "{\"system\":{\"set_relay_state\":{\"state\":1}
}
}" }
}

If you want to switch the plug Off, just replace the state 1 with state 0.
Notice how I have added extra carriage returns to separate the “}” at the end, otherwise IFTTT was giving me some error.
That’s it! Easy, right?
]]>Once you install and register the plug and the companion app (Kasa), you’ll be able to do some cool things like turn on/off the plug from your smartphone, schedule on/off at some time. You can also put the plug in Away Mode, so that the plug will randomly turn on/off in the specified time/date interval.
Kasa for Mobile (Free, Google Play) →
These are already really cool features, but I wanted to be able to do more with it: for example, turn on the plug when I arrive home, and turn it off 5min after I leave home. This is of course out of the scope of the Kasa app features, but I was more thinking about being able to control the plug from a smartphone automation App like Tasker, or a cloud service like IFTTT.
While there are some resources available explaining how to control the TP-Link HS100 plug from another device connected to the same Wifi network, I haven’t been able to find any that would explain how to do it via the TP-Link web service, so this is what I’ll show here.
In this post I’ll show how to change the relay state of the plug via command line from any device connected to Internet, not only from the local Wifi, which can then be called from a script, or from Tasker on Android.
Arquitecture
There are basically 3 components involved here:
- A web service from TP-Link
- The Kasa app that runs on your Smartphone, connected to Internet (via your Wifi network, or any network for that matter). It does (at least) two things:
- Periodically get the status of the plug (is it turned on/off), and show the status in teh app (green icon if the plug is switched on). This happens every two seconds, when the app is in foreground and visible.
- When the user toggles the switch from the app, it will send the new relay state change request to the TP-Link web service.
- The plug, connected to Internet via your wifi network: It will periodically contact the TP-Link web service for any status change, like a request to turn on/off.
Communication overview
This is how the Kasa app communicates itself with the TP-Link web service. In this case when the user switches the plug On, the app will send an HTTP POST request (over SSL) like this one:
POST https://eu-wap.tplinkcloud.com/?token=74adcc7e-64f7-47c1-a751-dece6d2f4704&appName=Kasa_Android&termID=c69d10e5-5307-4602-b2c8-eee8f3761238&appVer=1.4.4.607&ospf=Android+6.0.1&netType=wifi&locale=en_US HTTP/1.1 Content-Type: application/json User-Agent: Dalvik/2.1.0 (Linux; U; Android 6.0.1; XXPhoneModelXX) Connection: Keep-Alive Content-Length: 160 Host: eu-wap.tplinkcloud.com { "method":"passthrough", "params":{ "deviceId":"80067AC4FDBD41C54C55896BFA28EAD38A87A5A4", "requestData":"{\"system\":{\"set_relay_state\":{\"state\":1}}}" } }
To which the TP-Link server will respond (when successful):
{
"error_code":0,
"result":{
"responseData":"{\"system\":{\"set_relay_state\":{\"err_code\":0}}}"
}
}
As expected, almost instantly, the plug will switch On.
I have highlighted 4 fields/values in the request above. This values are specific to you and your plug. This is how the TP-Link web service identifies you and which of your plugs you want to switch.
- Token (token=74adcc7e-64f7-47c1-a751-dece6d2f4704): passed in the URL, this is acting as a authentication. The Kasa app obtains it from the TP-Link server when you log in to the service via the App. The user and passwords are not used anymore after that. All communications use the token.
- DeviceID (“deviceId”:”80067AC4FDBD41C54C55896BFA28EAD38A87A5A4″): passed in the Json payload, it references the device we wan’t to control.
- TermID (termID=c69d10e5-5307-4602-b2c8-eee8f3761238): ID of the Client (the Kasa app installed in that particular phone). This doesn’t seem to be a compulsory field.
- state: this is the desired state we want to put the relay into. 1 for On, 0 for Off.
Note: I have changed all the values shown above, to avoid having anyone control my plug by error. I have also formated the Json payloads.
Knowing that, we can now reproduce the same requests, for example using curl, from the command line (even in a Tasker task!). The TP-Link server will have aboslutely no way of telling of the request was originating from the Kasa app or a script.
Now, let see how we can call again the same request from a linux command line using curl. I have removed some parameters, like the User-Agent, and some others in the URL query string, and it still works, so I assume they eventually use them for statistical reasons only:
curl --request POST "https://eu-wap.tplinkcloud.com/?token=74adcc7e-64f7-47c1-a751-dece6d2f4704 HTTP/1.1" \
--data '{"method":"passthrough", "params": {"deviceId": "80067AC4FDBD41C54C55896BFA28EAD38A87A5A4", "requestData": "{\"system\":{\"set_relay_state\":{\"state\":1}}}" }}' \
--header "Content-Type: application/json"
Of course, we need a way to identify the value of this fields. That’s what I’ll cover below.
Data extraction
UPDATE (06/20/2017): this “Data extraction” part is now obsolete. I leave it here for historical purpose. Instead you can now follow the following steps:
OBSOLETE CONTENT STARTS HERE
This is what we’ll need:
- Android phone with Kasa app installed and already registred, with the plug added to the app
- Computer with some tools to unpack the Android Backup file (adb, python, sqlite3,…)
- Phone with adb enabled
First let’s take an Android Backup of the Kasa app:
adb backup -f backup.ab com.tplink.kasa_android
Now let’s unpack the backup with this one-liner:
dd if=backup.ab bs=1 skip=24 | python -c "import zlib,sys;sys.stdout.write(zlib.decompress(sys.stdin.read()))" | tar -xvf -
Now we just need to find the relevant information. I show you how to retrieve the values for each field:
- Token
$ sqlite3 db/iot.1.db "select token from accounts;"
74adcc7e-64f7-47c1-a751-dece6d2f4704
- deviceID
$ sqlite3 db/iot.1.db "select deviceAlias,deviceID from devices;"My Smart Plug|80067AC4FDBD41C54C55896BFA28EAD38A87A5A4
- termId
$ cat f/INSTALLATION
c69d10e5-5307-4602-b2c8-eee8f3761238
For people on Windows, some users reported in the comments below that you can use Android Backup Extractor (ABE) to extract the backup, instead of dd. See these links:
- https://sourceforge.net/projects/adbextractor/
- https://github.com/nelenkov/android-backup-extractor
- https://forum.xda-developers.com/showthread.php?t=2011811
OBSOLETE CONTENT ENDS HERE
Now, control the plug without the Kasa App
If you follow these steps above you can extract the token and device ID corresponding to your Kasa app and smartplug. You can now control the smart plug from anywhere, without the need to use the Kasa app. For example, you can use the curl expression below, after you replace the values with yours:
- Turn On the plug:
curl --request POST "https://eu-wap.tplinkcloud.com/?token=YOUR_TOKEN_HERE HTTP/1.1" \ --data '{"method":"passthrough", "params": {"deviceId": "YOUR_DEVICEID_HERE", "requestData": "{\"system\":{\"set_relay_state\":{\"state\":1}}}" }}' \ --header "Content-Type: application/json"
- Turn Off the plug:
curl --request POST "https://eu-wap.tplinkcloud.com/?token=YOUR_TOKEN_HERE HTTP/1.1" \ --data '{"method":"passthrough", "params": {"deviceId": "YOUR_DEVICEID_HERE", "requestData": "{\"system\":{\"set_relay_state\":{\"state\":0}}}" }}' \ --header "Content-Type: application/json"
Common issues
- AppServerURL: You’ll need to change the URL used to control the plug with the correct one specific for your plug: See how to find it here.
- [obsolete]{“error_code”:-20580,”msg”:”Account is not binded to the device“}: Some have reported issues with the URL eu-wap.tplinkcloud.com used in this tutorial. Here are all the known (to me) URLs of different TP-Link backend instances. If you have some problem like the previous error, try a different URL:
- use1-wap.tplinkcloud.com if you are near the US region
- aps1-wap.tplinkcloud.com if you are near the Asia Pacific region
- eu-wap.tplinkcloud.com if you are near the Europe region
- wap.tplinkcloud.com, without any region prefix[/obsolete]
- If you get an expired or invalid token error, logout from Kasa app, then login again with your account and extract again the token from the app. Some have needed to uninstall the app completely, reinstall it and start over.
- Be sure to enable Remote Control of the plug. You will find the option in the Kasa App, enter the Plug, then there’s a Plug settings button. There enable Remote control.
If you have any questions or comment, please, do not hesitate to let me know, using the comments below :).
In future posts I’ll show how to integrate your HS100 smart plug with the cloud Automation service IFTTT (see here), and how to control it from the Android Automation app Tasker or your Smartwatch, as well as how to get the state (On/Off) of the plug.
]]>Scalability is the capability of a system, network, or process to handle a growing amount of work, or its potential to be enlarged in order to accommodate that growth.
Looking at scalability is very relevant in Cloud environment, which provide a high level of on demand elasticity and thus allow us to easily implement the scalability patterns most relevant to our applications to cater for our particular business needs, whichever they may be.
App Service Plan Provisioning
Let first have a look at what happen when you provision a new App Service Plan in Azure.
When you request the creation of an Azure Web App onto a new App Service Plan (aka. Serverfarm), Azure is not provisioning a brand new VM from scratch. Instead, I believe, they assign you a recycled VM of the chosen size, for example B1, from a pool of existing VM.

Indeed you can see that by looking at the uptime of the provisioned VM instance (use Kudu advanced tools): uptime is quite random, and not near 0. A near 0 uptime would indicate a recently created VM. So, in my understanding, Azure keeps a pool of VMs just ready for when a new customer is requesting a new service plan, or when a scaling operation is needed.
That make a lot of sense. Provisioning a new VM each time would take quite a lot of time, while a new Web App deployment actually happens in about 15 to 20 seconds. For that purpose, I assume they will always keep a certain number of VMs ready in the pool, enough to respond to customer’s needs at all time in a timely manner.
Horizontal scalability (Scale out / Scale in)
Horizontal scalability is when you change the number of VM instances supporting your App Service Plan. When load on your apps grows, you will likely scale-out (add more VM instances). When the loads decrease, you will scale back in, reducing the number of VM instances.
As I understand it, when scaling-out, an operation similar to the provisioning will happen: Azure will assign you one new VM of the same size, from its pool of available VMs:

When the plan scales back in again, the VM is removed from the Plan and placed back in the correspondin pool. As I understand it, it is recycled so it can be reused again, possibly by another customer.

Vertical scalability (Scale up/down)
Vertical scalability is about changing the App Service Plan instance size. If you need more compute power to run you apps, you can choose to scale-up your plan to bigger VM(s). What happen in that case though?

AFAIK, Azure runs on Hyper-V virtualization platform, and at the time of this writing, Hyper-V doesn’t allow for dynamic CPU/RAM resizing of VMs. So how do they do it?
Well, I did the test on a Plan with a single small instance. I noticed the instance hostname and uptime before scaling up. I then scaled the plan up to medium, and guess what: the hostname and uptime of the only instance in the plan was totally different!
Here’s my educated guess: Azure assigned a medium VM from the pool of medium VM and added it to the Plan (1). All the Apps running in the plan started to run in that new VM as well. Only then, the small VM got removed from the Plan (2), leaving the plan with a single Medium VM.

We can also easily figure how it would happen with more than one VM. Scaling back in would also happen similarly.
App Service on Linux is currently in Public Preview and enables customers to run their web apps natively on a Linux platform. This allows for better application compatibility for certain kinds of applications and makes it easier to migrate existing web apps hosted on a Linux platform elsewhere onto Azure App Services.
In this third post in my series on Azure App Service Architecture, I’ll focus on how Microsoft implemented this new Platform as a Service product. What will actually run your app if you deploy it on Linux, what Linux distribution they have chose, and how are all the apps deployed on those underlying Linux servers. If you haven’t read my preview two articles, I strongly recommend you read them first: Azure App Service Architecture (1) and Azure App Service Architecture (2) as they will explain some basic concepts that are used in this one.
Provisioning a Web App on Linux
This part is really trivial. I’ll show some screenshots, but they are self explaining. Let’s click on the [+] button, and head to [Web + Mobile]. From there, we’ll select Web App on Linux (Preview):

I’ll set a new unique name for my new Web App:

To be able to explore a little further the options available to us, I’ll choose to create a new App Service Plan, instead of using the default recommended to me. Notice that while the product is in Preview, it is not available in all Azure regions yet. In Europe it’s only available in West Europe for example. That’s enough for me to test it anyway.

Particularly, I don’t need to pay for a Standard plan, so I’ll choose a Basic B1 here.

So here we go, just click the Create button, and in less than a minute, you’ll have a Web App up and running, ready for you to use to deploy your app, using your favorite Deployment method, Git, FTP…
App Service on Linux Architecture
To better understand what has been deployed by Azure, let’s head to the Development tools section of the Web App setting menu, and select Advanced Tools:

Then click on the Go link. It will open the traditional Kudu tools console, where we will have access to some internal information regarding our Web App.
Application layer
First let’s figure out what we have at the Application layer. That is, what kind of software is going to serve our application. In this case, from the Environment tab, we can see some interesting Server Environment Variables:
SERVER_SOFTWARE=Apache/2.4.10 (Debian)
So apparently the Web App is deployed on Apache 2.4 on Debian.
Let’s dig a little deeper with the Bash console, and have a look at the processes we can see:
Kudu Remote Execution Console Type 'exit' to reset this console. /home> ps -ef UID PID PPID C STIME TTY TIME CMD 1001 1 0 0 12:54 ? 00:00:00 /bin/sh -c /usr/sbin/apache2ctl -D FOREGROUND 1001 5 1 0 12:54 ? 00:00:00 /bin/sh /usr/sbin/apache2ctl -D FOREGROUND 1001 7 5 0 12:54 ? 00:00:00 /usr/sbin/apache2 -D FOREGROUND 1001 9 1 0 12:54 ? 00:00:00 /usr/bin/mono /usr/lib/mono/4.5/mod-mono-server4.exe --filename /tmp/.mod_mono_server4 --nonstop --appconfigdir /etc/mono-server4 1001 12 7 0 12:54 ? 00:00:00 /usr/sbin/apache2 -D FOREGROUND 1001 13 7 0 12:54 ? 00:00:00 /usr/sbin/apache2 -D FOREGROUND 1001 71 1 6 12:54 ? 00:00:08 /usr/bin/mono /usr/lib/mono/4.5/mod-mono-server4.exe --filename /tmp/mod_mono_server_default --applications /:/opt/Kudu --nonstop 1001 126 71 0 12:56 ? 00:00:00 /bin/bash -c ps -ef && echo && pwd 1001 127 126 0 12:56 ? 00:00:00 ps -ef
We can see very few processes running, and especially interesting, the PID 1 is apache2ctl, so we are most likely running is a container (if we were in a full server, it would be “init”). All the processes run as a non-root user (uid 1001).
We can indeed confirm that our Web App is running inside a Docker container by looking at /proc/1/cgroup:
/home> cat /proc/1/cgroup 11:memory:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b 10:cpuset:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b 9:hugetlb:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b 8:blkio:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b 7:perf_event:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b 6:net_cls,net_prio:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b 5:pids:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b 4:cpu,cpuacct:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b 3:freezer:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b 2:devices:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b 1:name=systemd:/docker/fb05a97d54930566111197c8959a5a33ac9af29b6491bf1ca8158b18df50264b
So, Web App on Linux are deployed in Docker containers (and we know the ID of the container in the host).
Unfortunately, there’s not much we can do from inside the Docker container itself to guess anything about the host running the Docker engine, so we don’t really know what is the OS flavor, version or anything else.
We can have a look at the kernel, which is shared between the VM (host) and all the containers run in the same VM:
/home> uname -a Linux e30a13645e09 4.4.0-45-generic #66-Ubuntu SMP Wed Oct 19 14:12:37 UTC 2016 x86_64 GNU/Linux
Regarding the Docker image that was used, we can see it’s based on Debian 8 (Jessie):
/home> cat /etc/os-release PRETTY_NAME="Debian GNU/Linux 8 (jessie)" NAME="Debian GNU/Linux" VERSION_ID="8" VERSION="8 (jessie)" ID=debian HOME_URL="http://www.debian.org/" SUPPORT_URL="http://www.debian.org/support" BUG_REPORT_URL="https://bugs.debian.org/"
Data layer: Persistent Storage?
Storage inside a Docker container is, usually, volatile, but if we deploy our App there, we don’t want to loose it when the container stops or the host reboots. Also, we want to be able to scale out our Web App when load increase. So we require some kind of persistency!
Similarly to Web App on Windows, where the persisted files are found in D:\home, here we’ll store the Persisted files in /home. As this Web App is recently created, it’s actually quite empty right now:
/home>pwd /home /home>ls LogFiles site
So how is the storage actually persisted?
/home> mount | grep /home //10.0.176.8/volume-46-default/20a35f31f26928286ecf/580efcc549c040228b254d82ab4ed6e1 on /home type cifs (rw,relatime,vers=3.0,sec=ntlmssp,cache=strict,username=dummyadmin,domain=RD0003FF1A594C,uid=1001,forceuid,gid=1002,forcegid,addr=10.0.176.8,file_mode=0700,dir_mode=0700,nounix,serverino,mapposix,mfsymlinks,rsize=1048576,wsize=1048576,actimeo=1)
We can see that the /home directory is actually a network shared volume mounted via CIFS protocol (I can only assume here it’s backed by Azure Storage). That way Azure will be able to scale out our Web App, deploying more containers based on the very same stateless image, mounting the same volume which is where our Web App files are deployed.
I think Microsoft might be using here a custom implementation of their Docker Volume Plugin for Azure File Storage. (I haven’t had time yet to play with it and see how similar (or not) things look with this Docker storage plugin). For the persistent storage, Microsoft is using Fileservers that export SMB shares mounted in the host. Those are then mapped as /home into the corresponding docker containers.
Putting everything together
Let step back now. This is how I see Microsoft implemented App Service on Linux. First when we only deploy 1 web app on a single instance:

Now, how does it look likes if we deploy multiple Web Apps in the same plan, and we scale out the Plan to two instances?

I hope this gave you a good understanding of how Microsoft implemented internally this new App Service on Linux product.
]]>Note: This article is based solely on information gathered from publicly available sources, mainly Microsoft Azure documentation site and Github, wrapped with my own understanding and conclusions.
Let’s have a look at what an App Service Plan is actually made of.
Compute
We’ve seen in the first post that the App Service Plan is formed of one or more VMs instances (which can be dedicated or shared depending on the Service Tier). Also we’ve seen you can deploy multiple apps to the same Plan. The apps will then all run on all the instances of the Plan.
Inside each VM Instance of the Plan, you Apps are deployed in Sandboxes:
- Sandbox mechanism
Azure App Services run in a secure environment called a sandbox. Each app runs inside its own sandbox, isolating its execution from other instances on the same machine as well as providing an additional degree of security and privacy.
The sandbox mechanism mitigates the risk of service disruption due to resource contention and depletion in two ways: it ensures that each app receives a minimum guarantee of resources and quality-of-service, and conversely enforces limits so that an app can not disrupt other concurrently-executing apps on the same machine.
Storage
From a storage perspective, and especially when it comes to scale-out (horizontally), it comes handy to understand what are the storage capabilities available to an App deployed in an App Service Plan. There are two kinds: Temporary storage, and Persisted storage.
- Temporary files
Whithin the context of the Application deployed in the WebApp, a number of common Windows locations are using temporary storage on the local machine. For instance:
%APPDATA% points to something like D:\local\AppData.
%TMP% goes to D:\local\Temp.
Unlike Persisted files, these files are not shared among site instances. Also, you cannot rely on them staying there. For instance, if you stop a site and restart it, you’ll find that all of these folders get reset to their original state.
- Persisted files
Every Azure Web App has a home directory stored/backed by Azure Storage. This network share is where applications store their content. The sandbox implements a dynamic symbolic link in kernel mode which maps d:\home to the customer home directory.
These files are shared between all instances of your site (when you scale it up to multiple instances). Internally, the way this works is that they are stored in Azure Storage instead of living on the local file system. They are rooted in d:\home, which can also be found using the %HOME% environment variable.
Now if we put everything together, let’s have a look at how it looks. First let’s start with a single App deployed on a Service Plan with a single VM Instance:

Now let’s see how it looks when we scale-out the plan to two VM instances. We can see how each instance of the App will have a separate Temporary storage in each VM, while they share the Persisted storage (where the App files are deployed).

How does it look if we now deploy multiple Apps to this same App Service Plan?

Notice how within its sandbox, every App in a same VM will keep seeing it’s persisted storage as D:\home, and the Temporary storage as D:\local. That’s quite nice!
Console Access
From Azure Portal you can access the App’s console: the Kudu tools give access to the Web site app at the sandbox level. From there you can access D:\local and D:\home. The hostname command shows the hostname of the VM (ie. the instance where the console is being connected to).

Azure App Services is a Platform-as-a-Service (PaaS) cloud service offering by Microsoft focused on providing superior developer productivity without compromising on the need to deliver applications at cloud scale. It also provides the features and frameworks necessary to compose enterprise applications while supporting developers with the most popular development languages (.NET, Java, PHP, Node.JS and Python). With App Service developers can:
- Build highly scalable Web Apps
- Quickly build Mobile App back-ends with a set of easy to use mobile capabilities such as data back-ends, user authentication and push notifications with Mobile Apps.
- Implement, deploy and publish APIs with API Apps.
- Tie business applications together into workflows and transform data with Logic Apps.

To be able to deploy any App on Azure App Service you’ll need an App Service Plan:
App Service Plans
An App Service Plan represents a set of features and capacity (compute, storage) that you can share across multiple apps. in Azure you deploy a Web App on an App Service Plan, which is formed of one or more (VM) Instance.
App Service Plans are specified by two characteristics:
- The Pricing Tier: from Free, Shared, Basic, Standard to Premium
- The Instance Size: from Small, Medium, Large to Extra Large
The Instance sizes define some compute and storage characteristics of the underlying VM instances that will form the App Service Plan. The CPU and Ram is the same for every Pricing Tier (Basic, Standard or Premium. In Free or Shared you can’t select the Instance Size). Here are the size available at the time of this writing:

The Pricing Tier define some other capacity characteristics as well as features and services that will be available to the App that we deploy in the Plan.

Note that in the Free and Shared tier, the VM Instances are shared in a multitenant fashion (possibly with other customers), while from Basic to Premium tiers, the VM Instances are dedicated.
Internally (in API documentation,…), App Service Plan are actually called “hosting Plan” or “serverFarm”, which reveal the true nature of what they really are.
Deployment model
From a deployment perspective, Apps in the same subscription and geographic location can share a plan. All the apps that share a plan can use all the capabilities and features that are defined by the plan’s tier. All apps that are associated with a plan run on the resources (VM Instances) that the plan defines:

Scalability Up & Out
Scalability of the App Service Plan is achieve either horizontally by adding more VM Instances to the Plan (Scale-Out), or vertically, by changing to a larger Instance Size (Scale-Up).
Scaling-Up is a manual action, which occurs without service impact. Scaling-Out can be done manually, scheduled to happen periodically, or automated based on some performance metrics (from the Plan itself, or other resources like the Storage, Service Bus,…).
I’ve dedicated a whole post to how Azure achieves Scalability of the App Service Plans.
Watch out for my next post where I’ll explain how App Service Plans are architected internally.
]]>Ideally, my requirements were:
- Backup should be offsite, preferably in the cloud
- Solution should support some kind of backup policies (full, incremental, and retention time)
- Solution should be secure, so support encryption
- Solution should be portable, so same solution would play nicely with the servers, not mess with their OS (dependencies,…)
- Solution should be as cheap as possible (or ideally free!)
For the offsite storage I first though of using AWS Glacier, a cloud storage meant for cold data that you archive, and don’t need to retrieve often, but the cost was not so cheap. While storage in itself was not too expensive, the cost of retrieving the data (in case you want to restore, which is the point of having a backup, right?), was kind of prohibitive (for the budget I had in mind). So I started to look for alternatives.
For the backup solution, I wanted to use duplicity. Duplicity supports full and incremental backups, using the rsync protocol, and have support for a lot of storage backend: file, FTP, SSH, AWS S3, Azure, Dropbox, OneDrive, Mega,… Most of those backends are either illimited but paid services, or free but rather limited (in capacity) storage. All but Mega, which offer for free 50GB of storage, which is quite nice for backup purpose. Perfect fit in my case.
Regarding the portability requirement, I love Docker containers, and all I deploy now for my personal projects is Dockerized. This wasn’t going to be an exception. Especially I’d hate to install all kind of dependencies for duplicity and the storage backend plugins in all my servers!
So Docker it would be.
Now back to the storage layer in our solution: although duplicity supposedly have support for a Mega backend, it seems Mega changed their API/SDK, and the current plugin is not working anymore, and would need to be reworked totally. So as an alternative, I turned to using MegaFuse, a Fuse module to mount Mega storage in Linux: so the idea is we first mount the Mega account as a filesystem in Linux, and then we use it as destination of our backup with duplicity (using the file backend). Not as cool as having duplicity talk directly to Mega, but that seems to work equally.
So to recap, we have a container with duplicity and MegaFuse. As the container is stateless, we’ll map some volumes from the host to the container so the container gets the needed information:
- /vol/dupmega/megafuse.conf, containing some config for MegaFuse, like the credentials to the Mega account (see below),
- As duplicity and MegaFuse both keep a local cache with some metadata, having those stored in the container would do no good, so I also put that in host mapped folder (/vol/dupmega/cache/duplicity/ and /vol/dupmega/cache/megafuse/)
- Of course, we want to backup the host, not the container, so we need to map that as well into the container to /source
The megafuse.conf contains:
USERNAME = [email protected]
PASSWORD = aV3ryComplexMegaP4ssw0rd
MOUNTPOINT = /mega
CACHEPATH = /dupmega/cache/megafuse
So the Mega account is mounted in /mega in the container, and the MegaFuse cache will be in /dupmega/cache/megafuse (host mounted volume).
Here is the Dockerfile I have used to create my duplicity container with MegaFuse support. Right now it’s not yet published to Docker Hub. Right now it’s very rudimentary, there’s not even a CMD.
FROM ubuntu:14.04
MAINTAINER Alexandre Dumont <[email protected]>
ENV DEBIAN_FRONTEND=noninteractive
RUN sed -i -e ‘/^deb-src/ s/^/#/’ /etc/apt/sources.list && \
echo “force-unsafe-io” > /etc/dpkg/dpkg.cfg.d/02apt-speedup && \
echo “Acquire::http {No-Cache=True;};” > /etc/apt/apt.conf.d/no-cache && \
apt-get update && \
apt-get -qy dist-upgrade && \
apt-get install -y libcrypto++-dev libcurl4-openssl-dev libfreeimage-dev libreadline-dev libfuse-dev libdb++-dev duplicity git g++ make && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* && \
git clone https://github.com/matteoserva/MegaFuse && \
cd MegaFuse && \
make
I use the following command to build the image:
docker build -t adumont/dupmega --no-cache=true .
And here’s the image:
REPOSITORY TAG IMAGE ID CREATED SIZE
adumont/dupmega latest 3bf1d313aa56 7 days ago 581.8 MB
I still have to work on simplifying the whole process of running a backup. For now, I do it rather manually, but it will become a script and be scheduled in cron most likely.
Right now that’s how I run it, notice the volume mapping from host to containers. Also notice the container has to run as privileged, so it can use Fuse from inside the container. The source to be backed up is mounted read-only (least privilege).
host# docker run --rm -h $( hostname ) -ti --privileged \
-v /vol/dupmega:/dupmega \
-v /root/.gnupg:/root/.gnupg \
-v /vol/dupmega/cache/duplicity:/root/.cache/duplicity \
-v /:/source:ro adumont/dupmega
Then from inside the container, I run:
mkdir /mega; MegaFuse/MegaFuse -c /dupmega/megafuse.conf &>/dev/null &
sleep 10
[ -d /mega/backups/$(hostname) ] || exit 1
export PASSPHRASE=AnotherVeryComplexPassphaseForGPGEncrypti0n
and finally the duplicity command which will backup /source to /mega. The command is different for each server, as I tweak which files/folders I want to include/exclude in the backup:
duplicity --asynchronous-upload \
--include=/source/var/lib/docker/containers \
--include=/source/var/lib/plexmediaserver/Library/Application\ Support/Plex\ Media\ Server/Preferences.xml \
--exclude=/source/dev \
--exclude=/source/proc \
--exclude=/source/run \
--exclude=/source/sys \
--exclude=/source/zfs \
--exclude=/source/mnt \
--exclude=/source/media \
--exclude=/source/vol/dupmega/cache \
--exclude=/source/tank \
--exclude=/source/vbox \
--exclude=/source/var/lib/docker \
--exclude=/source/var/lib/plexmediaserver/ \
--exclude=/source/tmp \
--exclude=/source/var/tmp \
--exclude=/source/var/cache \
--exclude=/source/var/log \
/source/ file:///mega/backups/$(hostname)/ -v info
And this would be a sample output:
Local and Remote metadata are synchronized, no sync needed.
Last full backup date: Thu Oct 20 22:51:23 2016
Deleting /tmp/duplicity-Cwz5Ju-tempdir/mktemp-0lEM40-2
Using temporary directory /root/.cache/duplicity/185b874acbbae73c5807a4cc767e4967/duplicity-kYzeVT-tempdir
Using temporary directory /root/.cache/duplicity/185b874acbbae73c5807a4cc767e4967/duplicity-jWJXmd-tempdir
AsyncScheduler: instantiating at concurrency 1
M boot/grub/grubenv
A etc
A etc/apparmor.d/cache
M etc/apparmor.d/cache/docker
[...]
---------------[ Backup Statistics ]--------------
StartTime 1477499247.82 (Wed Oct 26 16:27:27 2016)
EndTime 1477499514.97 (Wed Oct 26 16:31:54 2016)
ElapsedTime 267.15 (4 minutes 27.15 seconds)
SourceFiles 449013
SourceFileSize 3239446764 (3.02 GB)
NewFiles 75
NewFileSize 189457 (185 KB)
DeletedFiles 135
ChangedFiles 68
ChangedFileSize 176144101 (168 MB)
ChangedDeltaSize 0 (0 bytes)
DeltaEntries 278
RawDeltaSize 9317325 (8.89 MB)
TotalDestinationSizeChange 1913375 (1.82 MB)
Errors 0
-------------------------------------------------
And backup are really stored on Mega  :
:
